Video Annotation Services
Delivering quality service with vast experience in providing annotated datasets using various types of data annotation over the years.
Delivering quality service with vast experience in providing annotated datasets using various types of data annotation over the years.
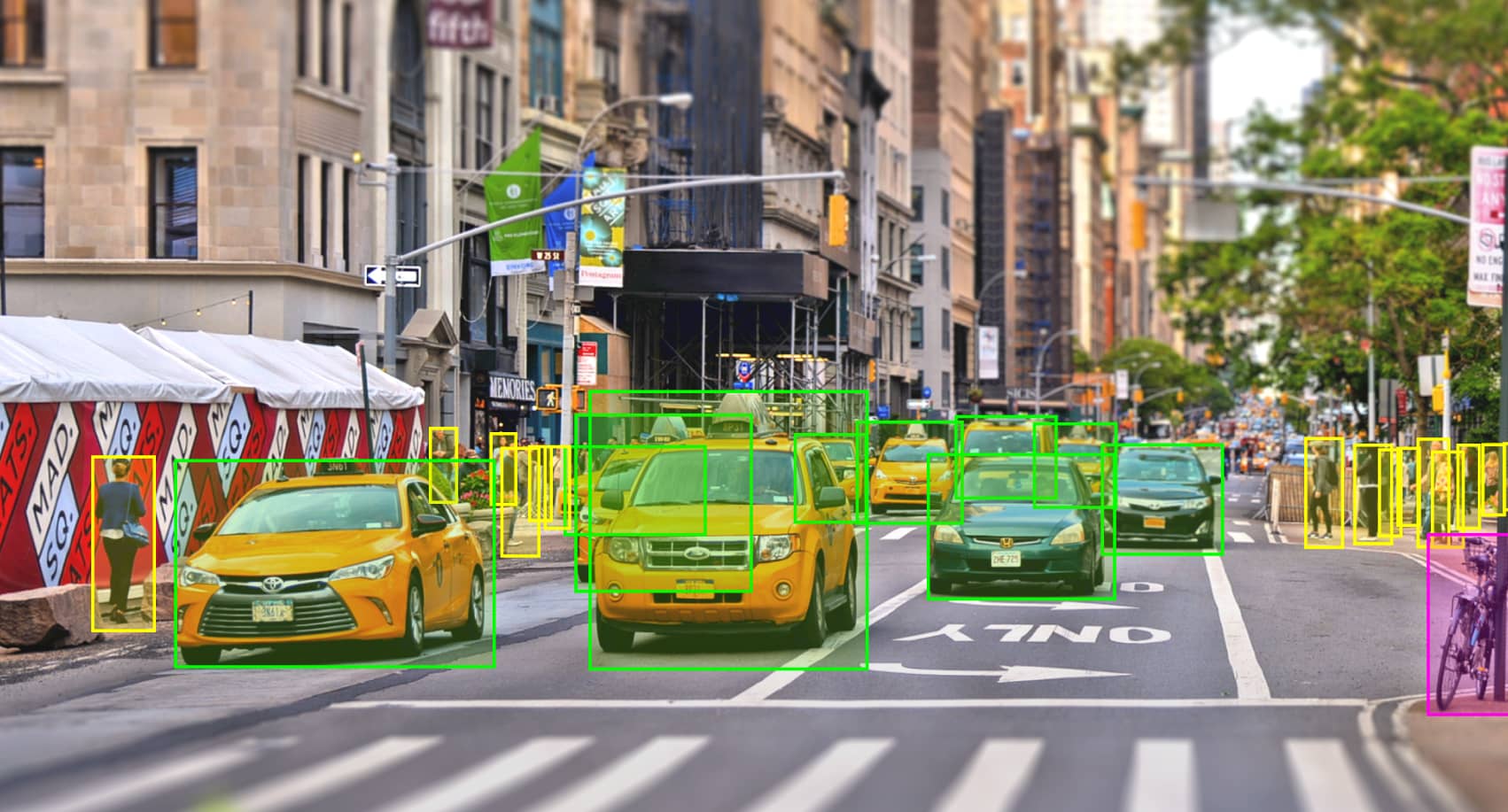
The technique of tracking, recognising, and classifying every object, body, tool, or instrument visible on video footage is known as video annotation. In the training of computer vision models, video annotation is extremely important. Breaking down the video into frames and preparing all of these frames using various ways is required for video annotation for machine learning. The actual number of frames that must be annotated will be determined by the video's duration and frame rate (fps). Because of the intrinsic semantic complexity, volume of data in videos, hundreds of potential classifiers, and data set quality compliances, among other things, it's more difficult than picture annotation
Triyock provides Video Annotation Outsourcing Services to assist businesses in improving machine learning technologies such as self-driving cars, human monitoring algorithms, and surveillance. In fields such as healthcare, robotics, geospatial technology, and autonomous technology, we've worked with numerous significant organisations and Fortune 1000 firms.

Our services also include entity linking, phrase crunching, semantic segmentation, Classification, event Tracking, object localization, data labelling, image annotation, and related services to meet your business requirement.
This annotation approach includes superimposing a rectangular 2D box over each frame's object of interest, which aids the system in identifying the things in the actual world
3D boxes provide the system with more information about the items in the image, such as their length, breadth, and height. As a result, it is significantly more accurate than the previous 2D box technique. It is frequently used to annotate movies for the automobile industry in order for the system to comprehend the traffic condition. Algorithms for the operation of robots and drones are also created with this technology.
This annotation technique is used to draw lines between different parts of an image. It can, however, be utilised for annotations in which a specific region has to be tagged as a border.
Polygons can be used to annotate oddly shaped photos that don't fit into rectangular frames. It recognises the object's actual shape and size, as well as ensuring more precise localisation.
Using this strategy, keypoints are placed over the region of interest. For motion tracking, face landmark detection, and hand gesture identification, precisely identify form changes.
The objects in the frames are tagged or labelled with data annotations and is widely known as Object Detection. This teaches the machine learning system how to recognise real-world items.
Our expert video annotation services empower organizations across multiple industries by delivering precise, frame-by-frame labeled data for training robust computer vision models.
Train self-driving algorithms with bounding boxes, lane tracking, and semantic segmentation for safer navigation.
Enhance surgical robotics and diagnostic AI with precisely annotated medical imaging and endoscopic video data.
Optimize cashier-less checkout, customer tracking, and inventory management with behavioral video analysis.
Improve threat detection and crowd monitoring algorithms through accurate action recognition and object tracking.
Enable advanced player tracking, pose estimation, and automated highlight generation for sports analytics.
Power smart farming equipment with video data labeled for crop health analysis, weed detection, and harvest automation.
Streamline supply chains and assembly lines with defect detection and robotic process automation video labeling.
Get best video labelling services at 50% ROI.
With the help of a worldwide workforce, Triyock’s experts can scale up your machine learning initiatives to satisfy any unique customer requirement through its Video Annotation Services.
Because our teams specialise in video annotation, we can provide you with services at a fraction of the expense of doing it in-house.
Only reliable and time-tested quality management methodologies and control measures are used by our outsourcing organisation. We provide 24x 7 customer services.
Triyock's systems are entirely secure, ensuring that our clients' data is kept safe. Use Triyock Video Annotation Services with guarantee of 100% security of your data.
When you outsource to Triyock for Video Annotation Services, you have access to our highly skilled team of annotators. We have the ability to handle large amounts of complicated data while maintaining accuracy. Our Quality Assurance team ensures that every job is completed with the utmost professionalism.
Triyock BPO delivers highly accurate and scalable video annotation services backed by state-of-the-art tooling, domain expertise, and a skilled workforce. Our frame-level precision ensures your computer vision models perform flawlessly in the real world.
Accurate video annotation is the backbone of reliable AI models. Our services provide the ground truth needed for:
Speak with our experts today and get a free end-to-end service quote tailored to your business needs.
Our experts realise the value of your data and provide you reliability and precision. Talk to our experts now
we create business process that are scalable and adaptable. With our end-to-end outsourcing services, we help you to improve operational agility.